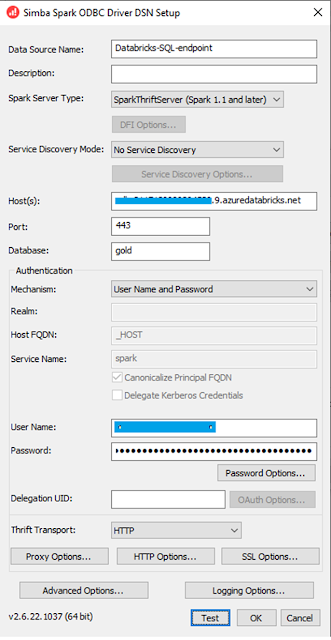
In this blog post, I will go through how we can build
real-time video analytics on IoT Edge devices with OpenVINO.
Before I start, let me explain what is OpenVINO and what is
good for?
OpenVINO stands for Open Visual Inference and Neural network
Optimization.
As its name suggests, it is used to optimize the models and allows
you to host the models based on your process architecture.
There are two main steps given below:
1.
Convert your favorite model
to IR format as shown below:

2.
Host your IR (intermediate
representation) to the OpenVINO model server. The runtime is process
architecture dependent.
With this approach, you can develop your own model with your
favorite framework or download the prebuilt models from Model Zoo and host them
in OpenVINO.
You can read more at https://docs.openvino.ai/latest/index.html
Now we know the OpenVINO, let’s see how we can use it for
IoT Edge. We can host the OpenVINO model in a Docker container which makes it
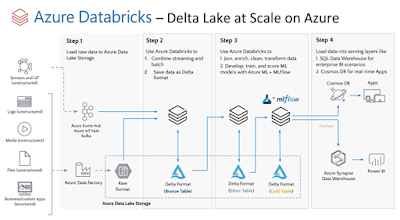
perfect for IoT Edge devices. The below diagram shows the general architecture of
how OpenVINO can be used:

For more information on how OpenVINO can be used with Azure IoT Edge please visit https://docs.microsoft.com/en-us/azure/azure-video-analyzer/video-analyzer-docs/edge/use-intel-openvino-tutorial
Now let’s see how we can host the model and how we can consume it to make inference for given video frame. For the example, I have chosen a prebuilt model called “Vehicle Detection” from Model Zoo.
Run below command to host model in a Docker container:
$ docker run --rm -d -v "path/to/your/models":/models:ro
-p 9000:9000 -p 9001:9001 openvino/model_server:latest --config_path
models/config.json --port 9000 --rest_port 9001
You can see OpenVINO documentation for more information: https://docs.openvino.ai/latest/ovms_docs_docker_container.html
Once the model is hosted you can query the metadata of the
model by navigating to the URL
http://iotedgedevice-ip:9001/v1/models/vehicle-detection-0202/versions/1/metadata
and response will be as shown below:

Which shows the shape of input and output. It means our
vehicle detection model is hosted.
Now let’s consume this model from the python script (which later
will be converted to the IoT Edge module to process the frame).
The first step is to load the frame in the OpenCV object as shown
below:


The endpoint for model prediction is at http://iotedgedevice-ip:9001/v1/models/vehicle-detection-0202/versions/1:predict
We need to submit this image as JSON data and get the result
as JSON which contains a NumPy array as per the specification mentioned at https://docs.openvino.ai/latest/omz_models_model_vehicle_detection_0202.html
The below method is used to convert an image to JSON input
for the model:

The code flow is shown below:

Here is the model that predicted the vehicle bounding boxes
which are then drawn to the mage as shown below:

We can see the model predicted all those vehicles shown in the above image.
That’s it for now and thanks for reading my blog.