In this blog post, I am going to show how we can use LLM using RAG (Retrieval-augmented generation) technique to answer the questions from our documents/files/web pages/data sitting in a private network.
With RAG architecture, your LLM is not required to train on your data but your provided data as additional context to LLM by asking to answer it.
Here is the RAG architecture:

Here is a simple method to interact with the OpenAI LLM model,
you need to define the OpenAI key:

Let's start with a simple prompt without context:

As we can see the LLM can’t answer if you ask any specific
question.
Now pass some context with a prompt to the LLM and see the
response:

We can see LLM answered it correctly.
Let's see how we can introduce some sort of database that stores
all your private/intranet data which LLM does not know about or LLM did not
use during the training.
To find the right context information for a given question, we
will be using Vector DB which stores the data as embedding vectors. Please read
more at Word embedding -
Wikipedia
Let’s use a simple example to understand how we can find the
relevant context. I am using OpenAI embedding here. Assume we have got two different
context information and one question as shown below:

The above code snippet shows the sentences are converted to the numeric vectors which is an embedding vector. We need to find which context is
similar to the question. We can do this using cosine similarity using the below
code:

We can see question and context 1 has the highest value for similarity
than to context 2.
I have a simple chatbot using LangChain, Chroma (an open-source vector db) OpenAI
embedding and gpt-3.5-turbo LLM to ask any question related to my website (https://www.musofttech.com.au)
Here is the output of a few questions I have asked:
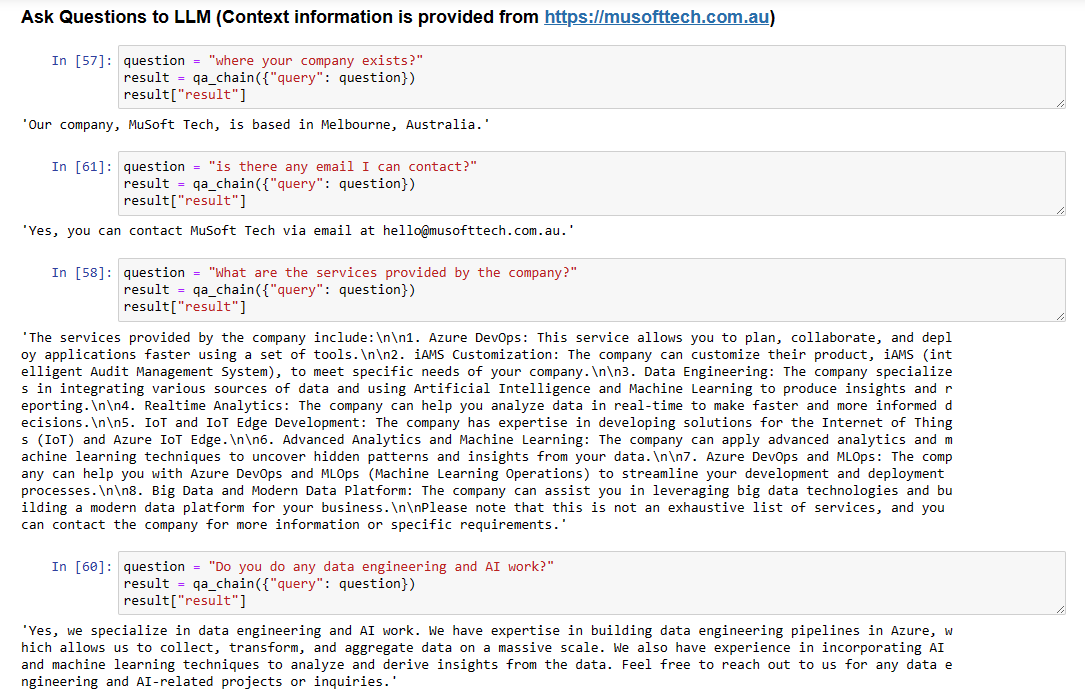
Now I am asking a question where the website does not have
information or context and see how the LLM is responding to it

One last thing, you can use LLM to ask about your
intranet/private data but we have to pass the context to LLM so make sure you
are not passing any information which are not supposed to go beyond your
network. The better option is to have your LLM deployed in your private
network so it will be safe to use.
Thanks for reading the blog and let me know if you want to achieve a similar thing for you or your customers.












